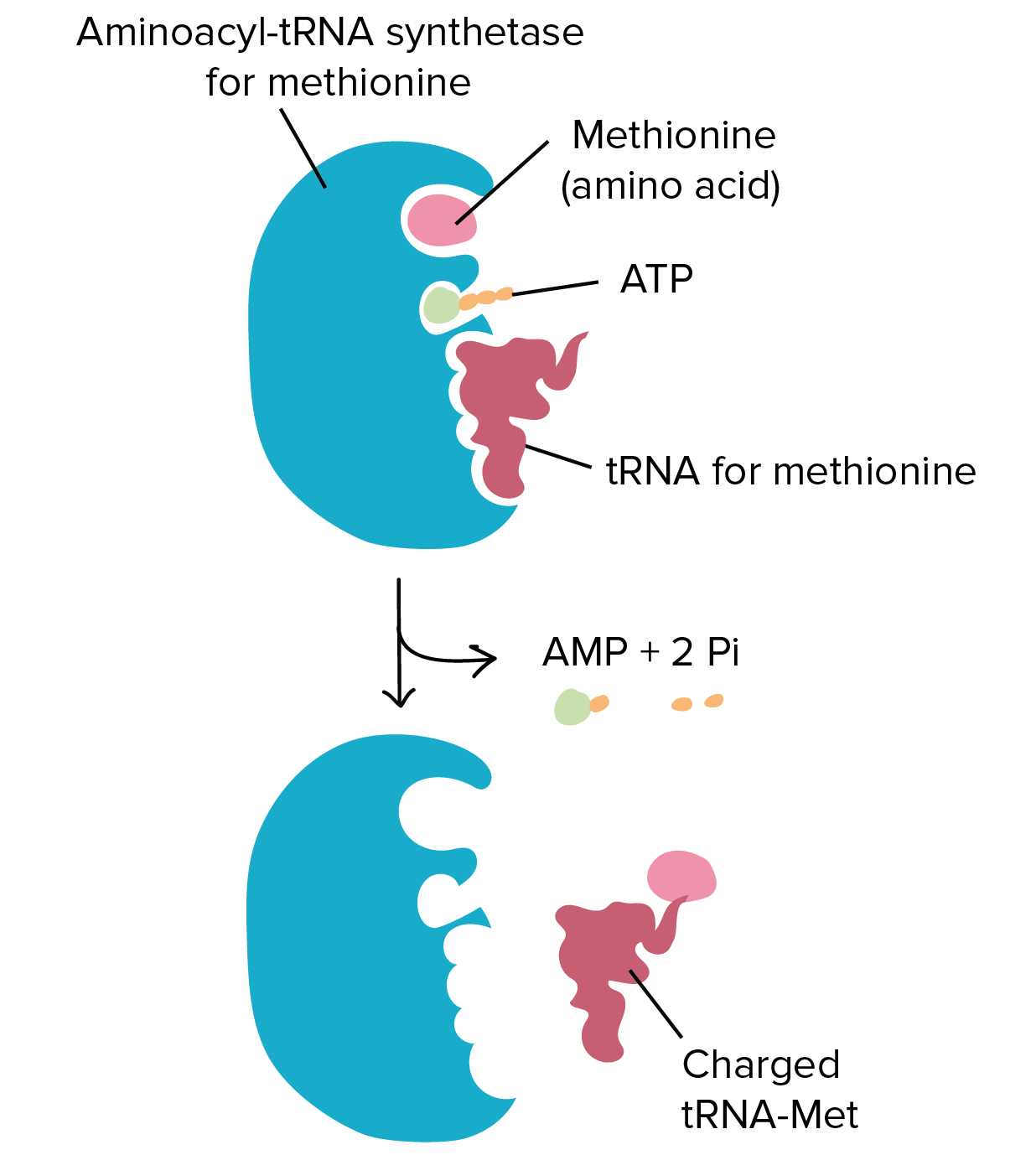São Paulo, 16 Setembro de 2020.
E.E Maria Montessori.
Atividade de Educação Física.
Turmas: 7°C
Prof. Luciana
Entregar a atividade por e-mail : prof.luedfisica@yahoo.com.br.
Coloca nome, nº e serie.
Data da
entrega 21/09.
Atividade p/ nota e presença do 3° Bimestre.
SITUAÇÃO DE APRENDIZAGEM –
ESPORTE TÉCNICO COMBINATÓRIO E DE PRECISÃO:
UM NOVO OLHAR!
Habitualmente, quando falamos em Esporte, sempre pensamos em
modalidades que se caracterizam pelo confronto e disputa, ou em esportes que
predominam em nosso país, como o futebol. Agora, você terá a oportunidade de
aprender sobre o esporte técnico combinatório GR (Ginástica Rítmica) e de
precisão: Bocha e Boliche. Para isso, é importante que você conheça melhor suas
definições a seguir:
Técnico-combinatório: reúne modalidades onde há
a comparação de desempenho de acordo com a dimensão estética e acrobática do
movimento, obedecendo a determinados padrões ou critérios (ginástica artística,
ginástica rítmica, etc.). (GONZALES,2014).
Precisão: conjunto de modalidades que se caracterizam por
arremessar/lançar um objeto, procurando acertar um alvo específico, estático ou
em movimento, comparando-se o número de tentativas empreendidas, a pontuação
estabelecida em cada tentativa (maior ou menor do que o do adversário) ou a
proximidade do objeto arremessado ao alvo (mais perto ou mais longe do que o
adversário conseguiu deixar) como nos seguintes exemplos: bocha, curling, tiro
com arco, esportivo etc. (GONZALES,2014).
Atividade I. O QUE VOCÊ JÁ
SABE?
Agora
que você já sabe que a Ginástica Rítmica faz parte dos Esportes Técnicos
combinatórios, vamos explorar alguns conhecimentos adquiridos acerca desta
prática corporal ao longo de sua vivência escolar e/ou na comunidade. Para
isso, você deverá responder as questões abaixo.
- Você
já praticou algum tipo de ginástica anteriormente? Qual?
- . Em
quais locais você praticou as modalidades de ginástica?
- Em
algum momento da sua vida, você realizou movimentos envolvendo: equilíbrio,
saltos, giros, acrobacias, com ou sem materiais?
- . Você
já experimentou alguma vivência coreográfica? Conte mais sobre isso.
Pesquisar:
- -Qual a história da Ginástica Rítmica?
- - Quais as habilidades e as regras da Ginástica Rítmica?
- - Quais são os aparelhos utilizado na Ginástica Rítmica?
- Quais são as competições e as categorias da
Ginástica Rítmica.
- Quem pode participar a Ginástica Rítmica.
- - Quais são as caraterísticas dos principais
gestos técnicos e movimentos da Ginástica Rítmica?
- Quais são os tipos de Ginástica que existem?
- - O que
é Ginástica Rítmica e Ginástica Artística?
- - Qual a importância da música na Ginástica
Rítmica?
Qualquer dúvida só chamar no grupo whastaspp (11) 998940458
Entregar no e-mail prof.luedfisica@yahaoo.com.br.
Bom trabalho.




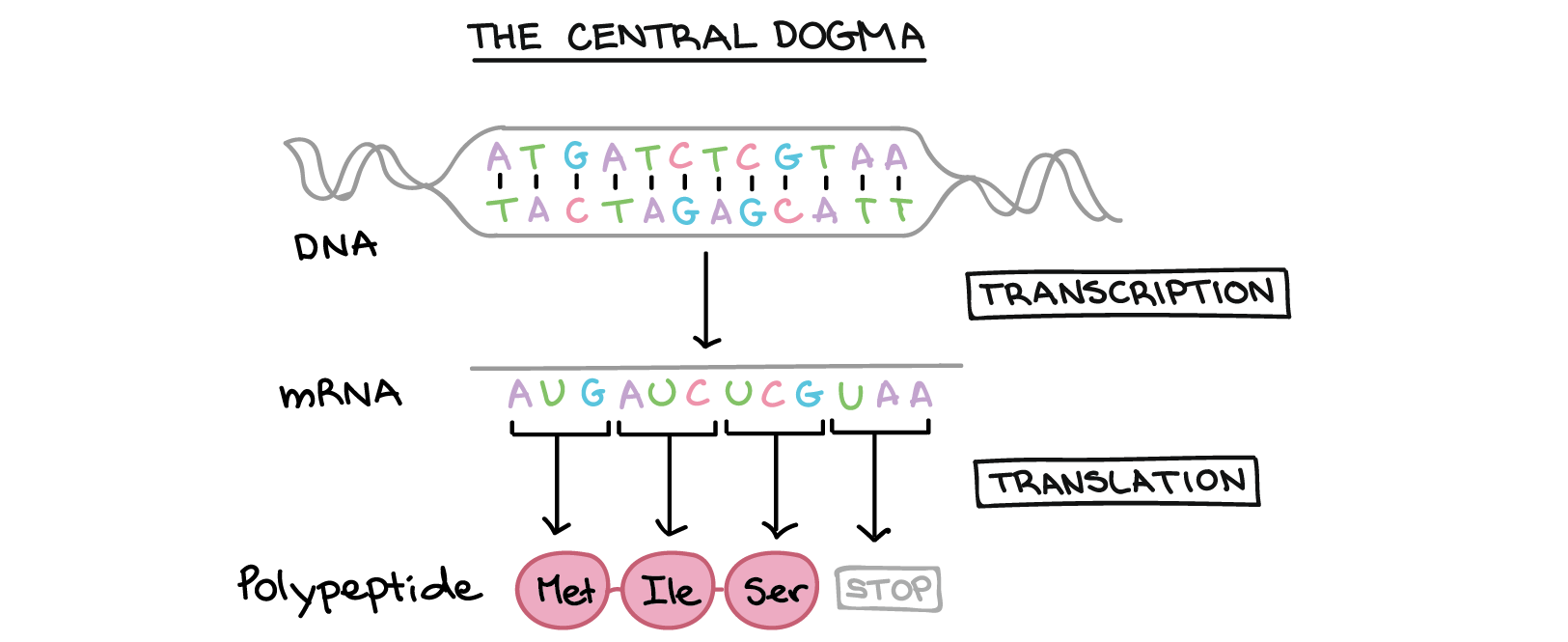
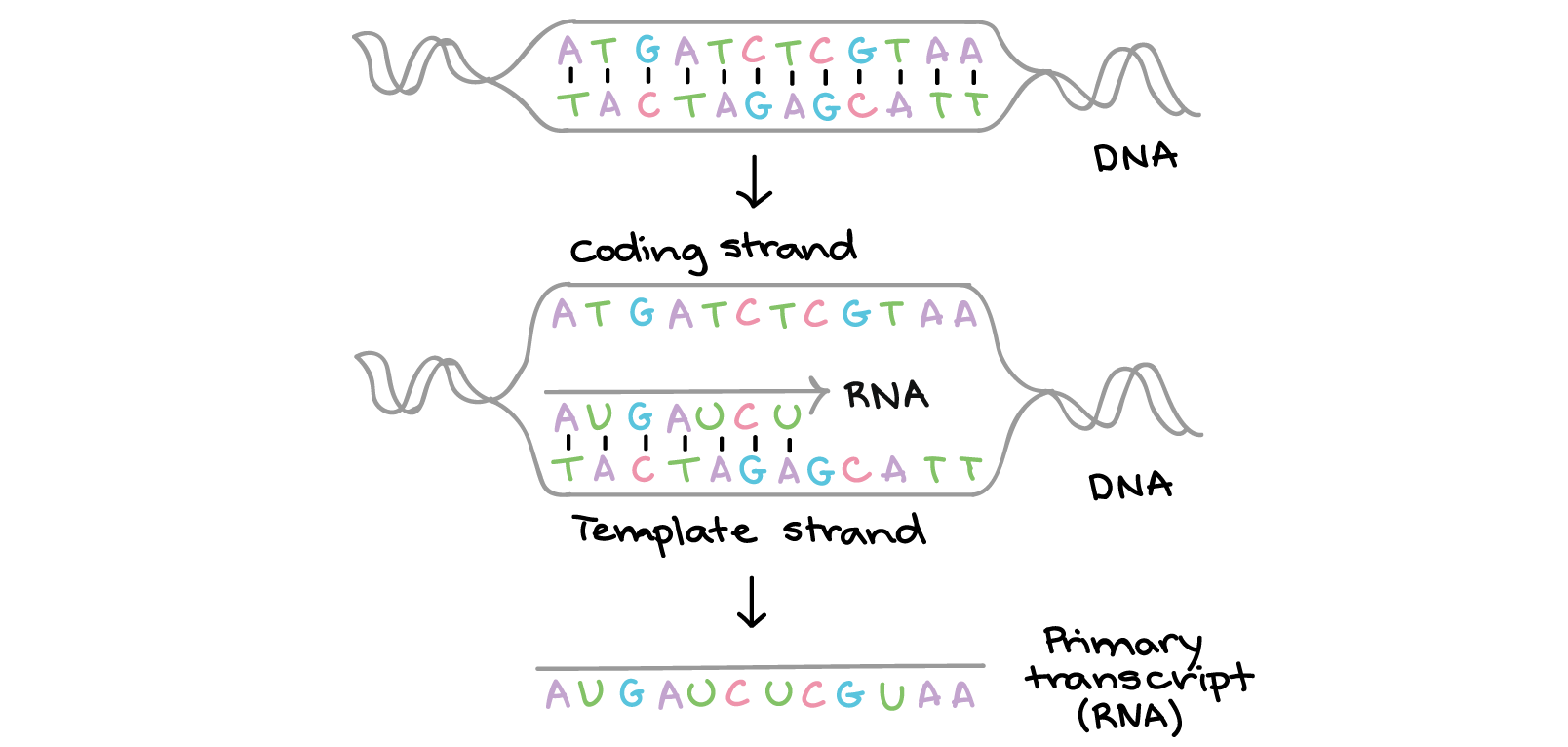
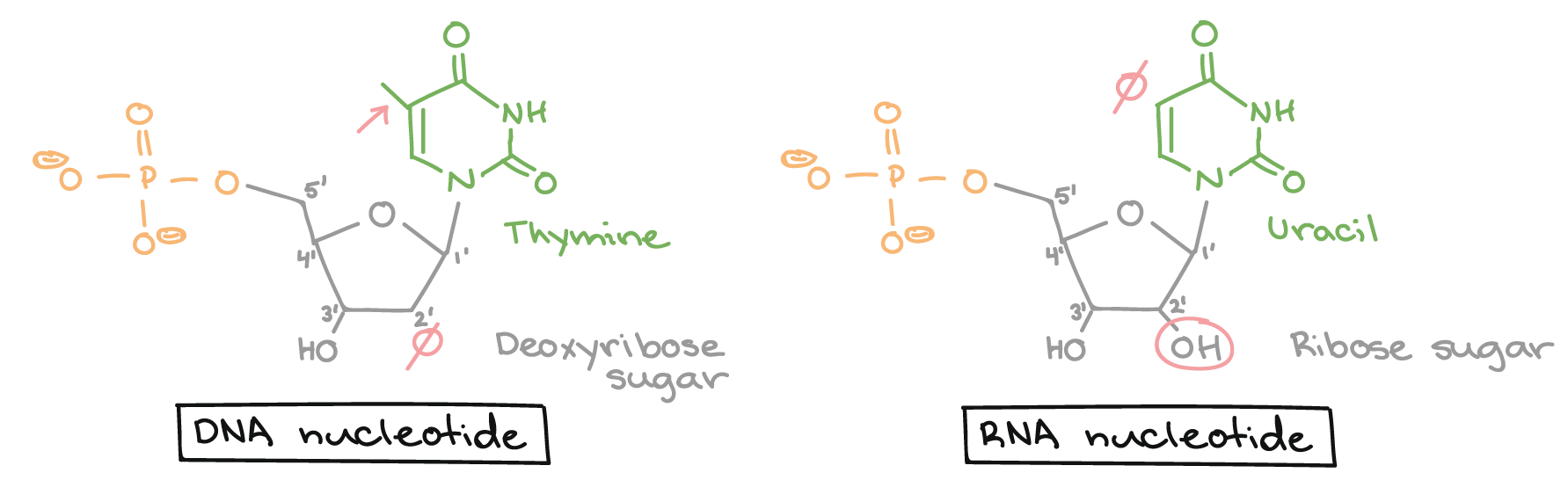
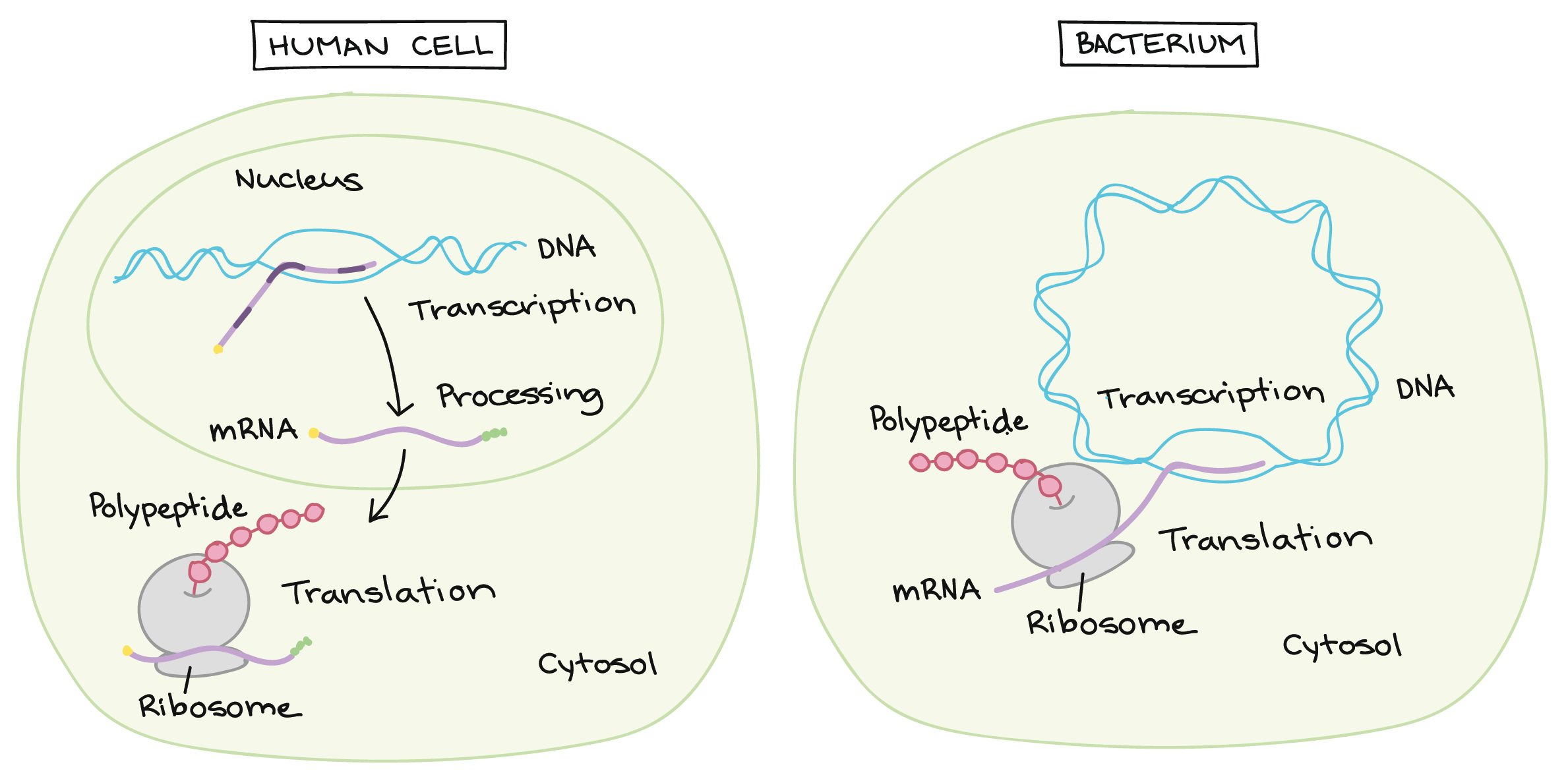
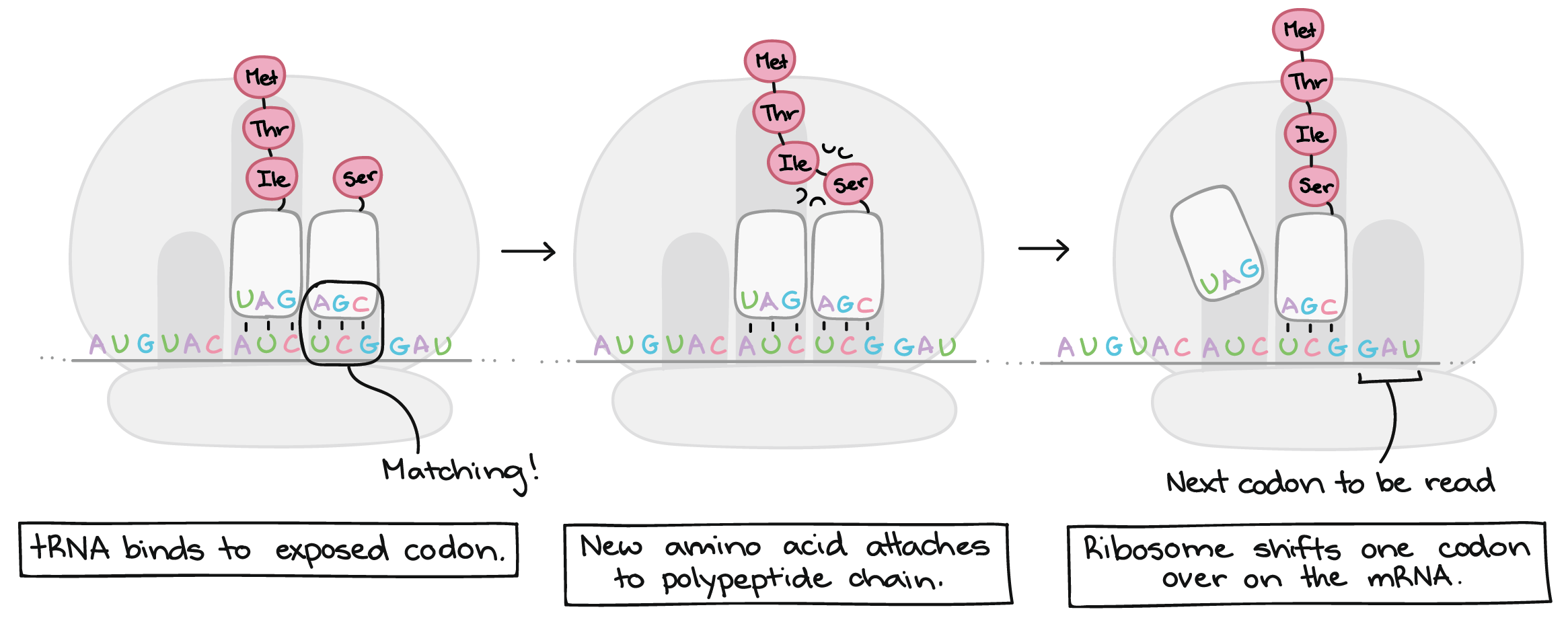
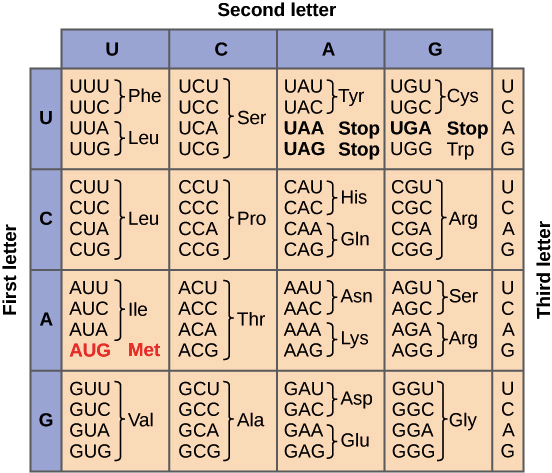

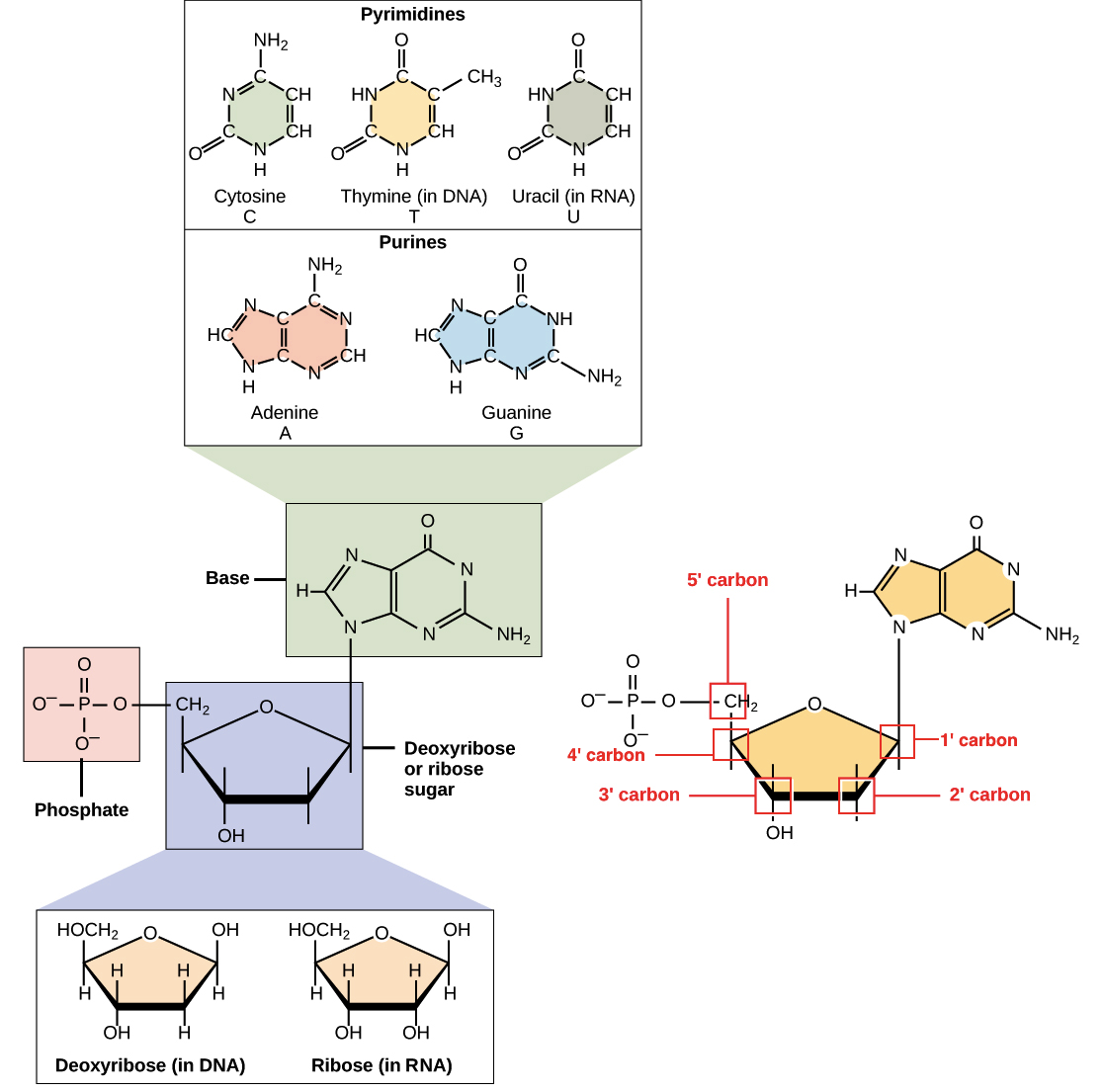
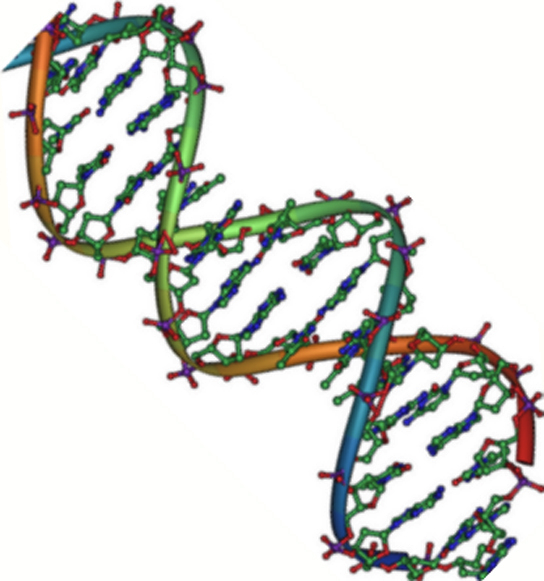

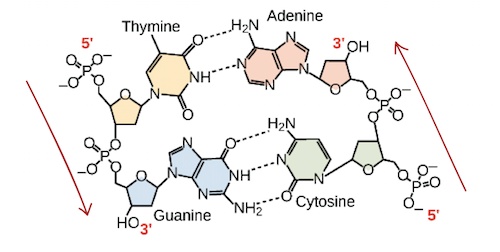
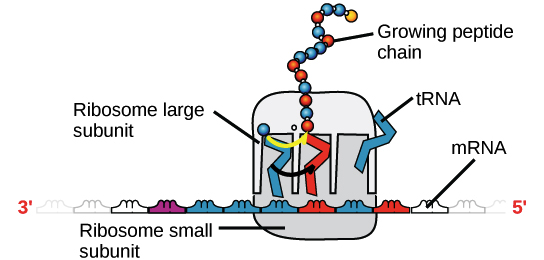
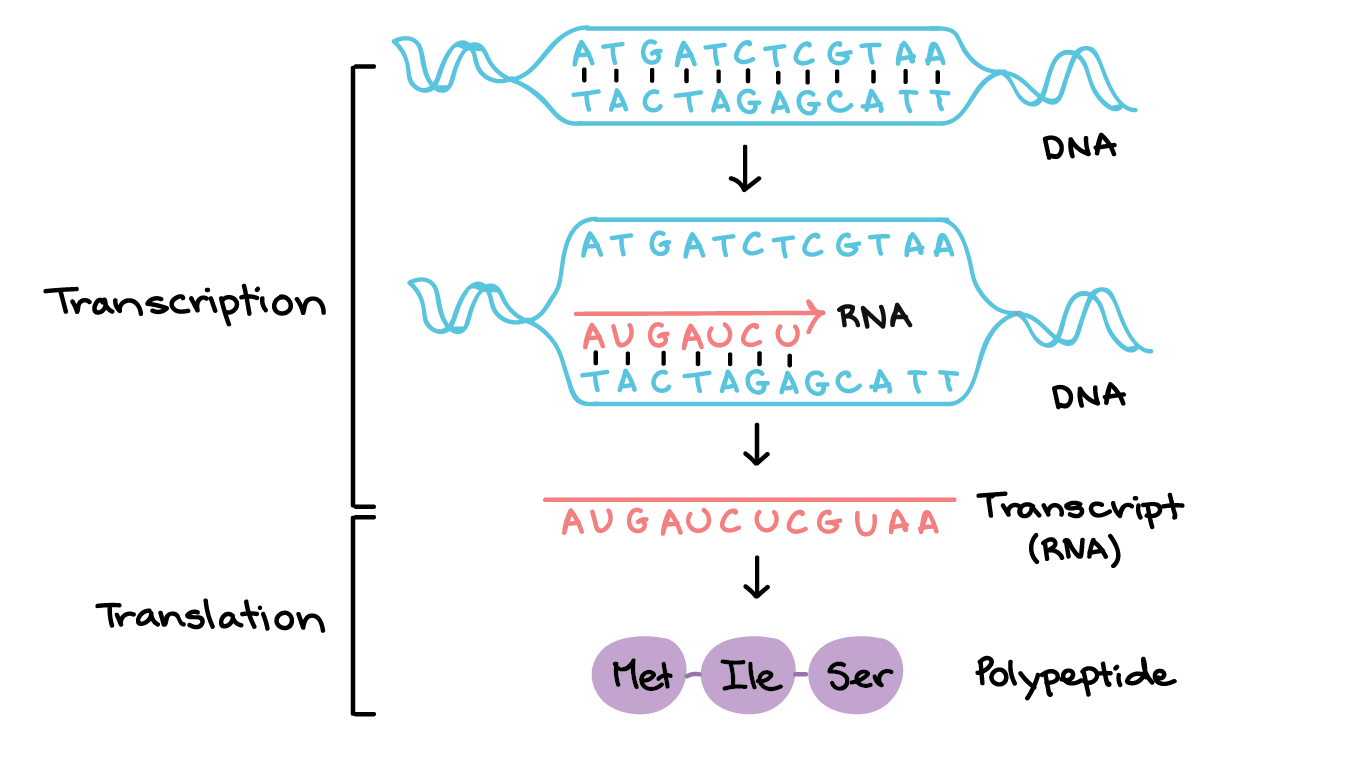
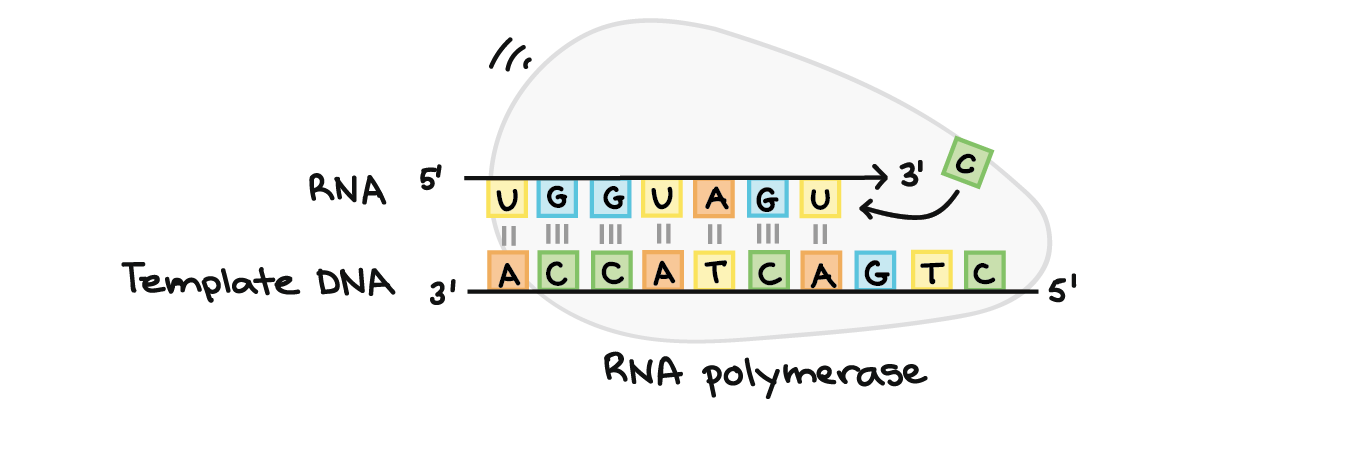
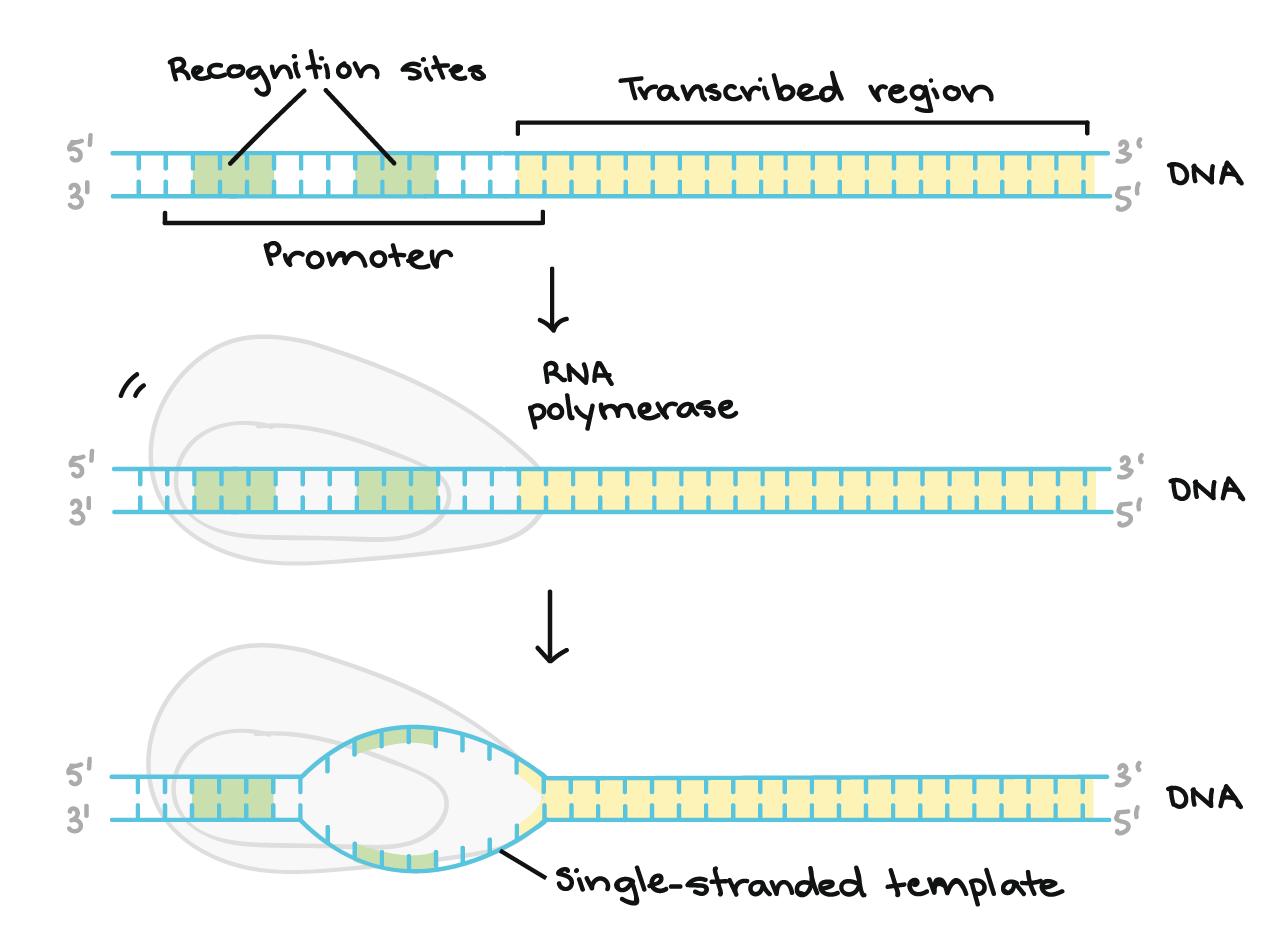
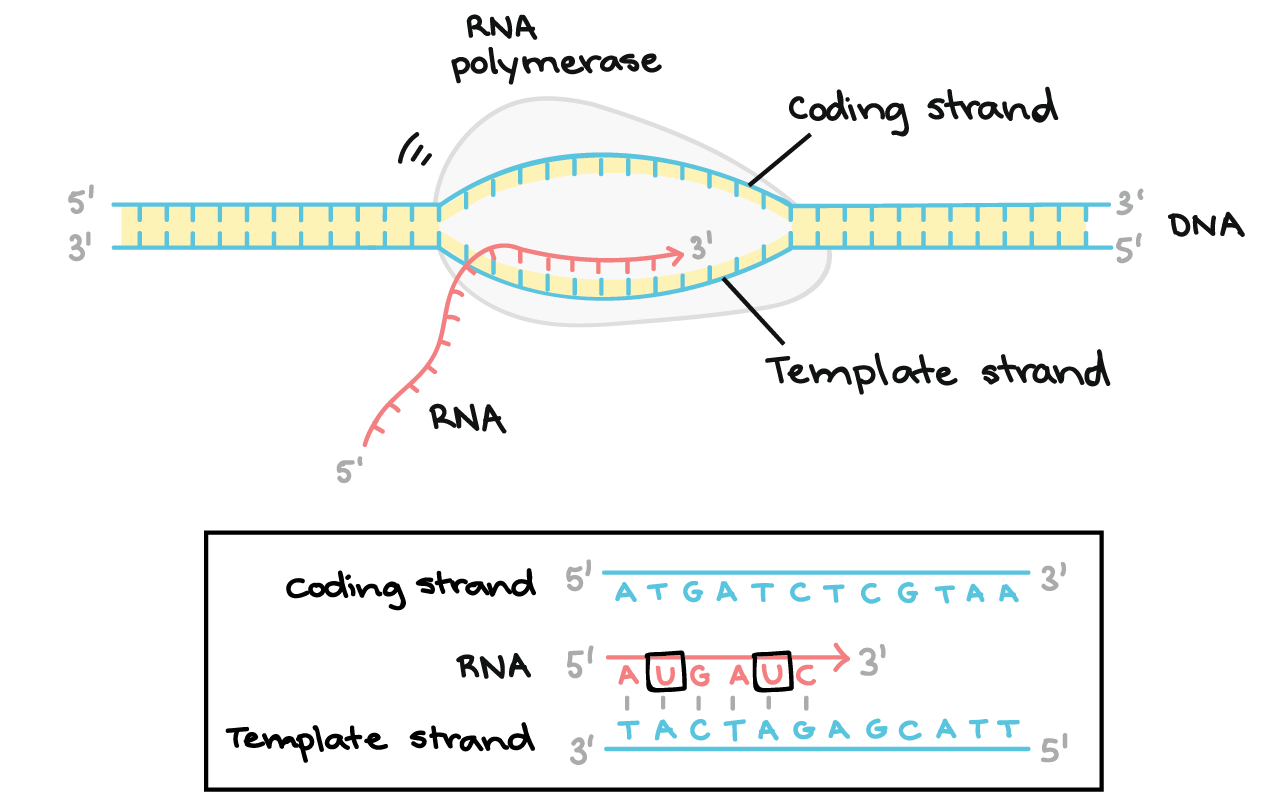
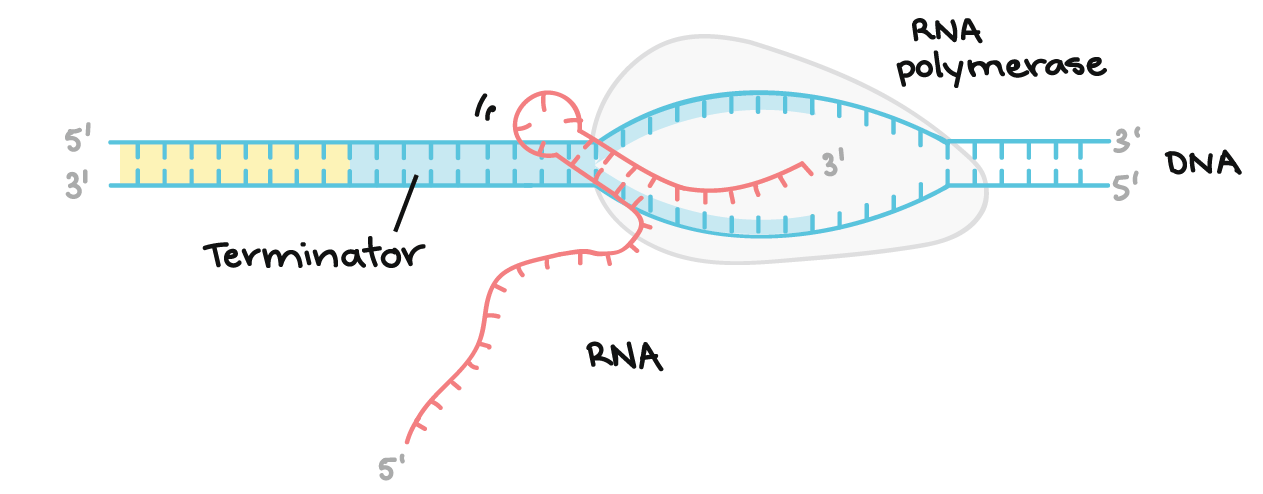
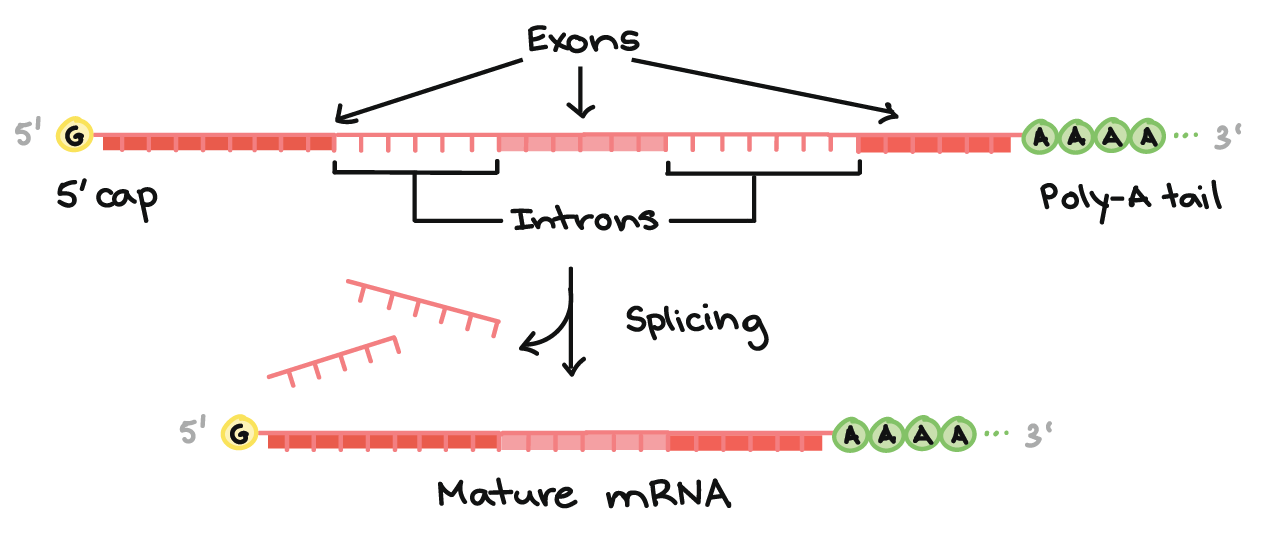

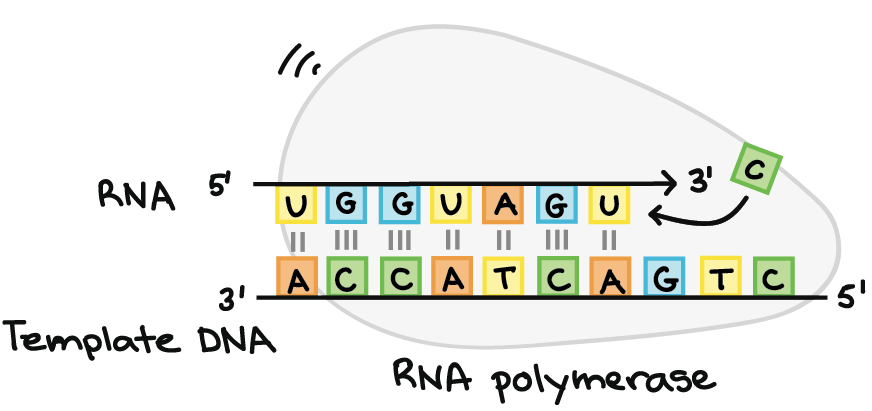
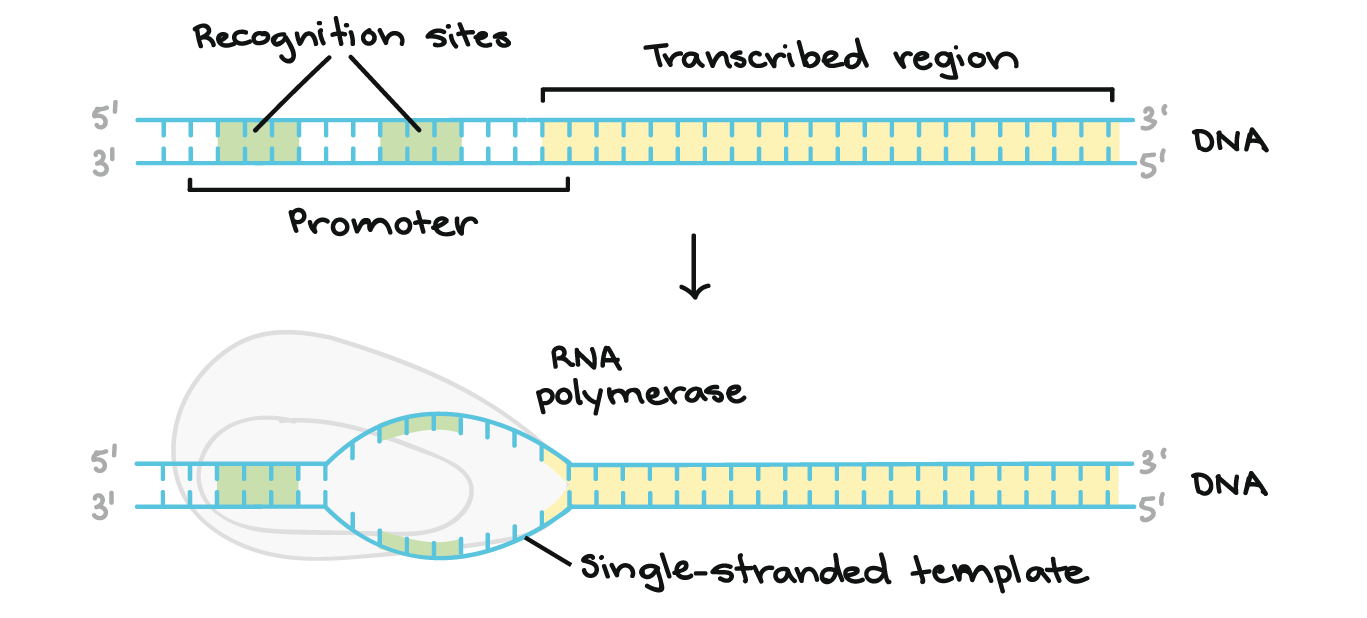
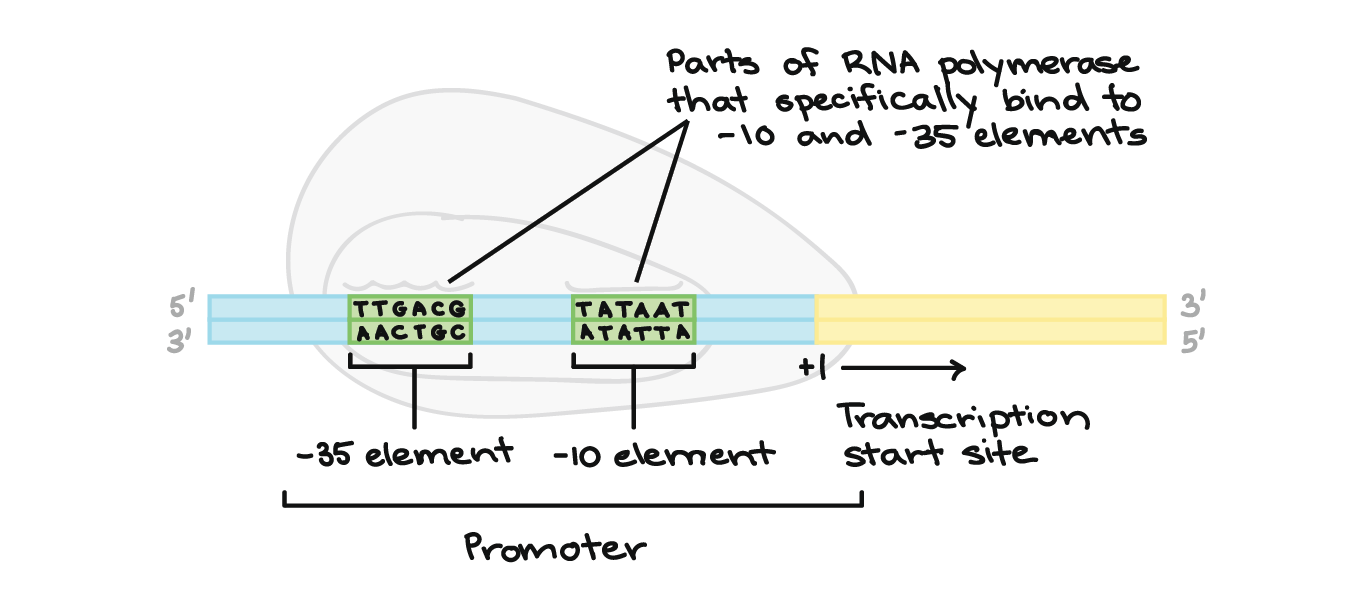
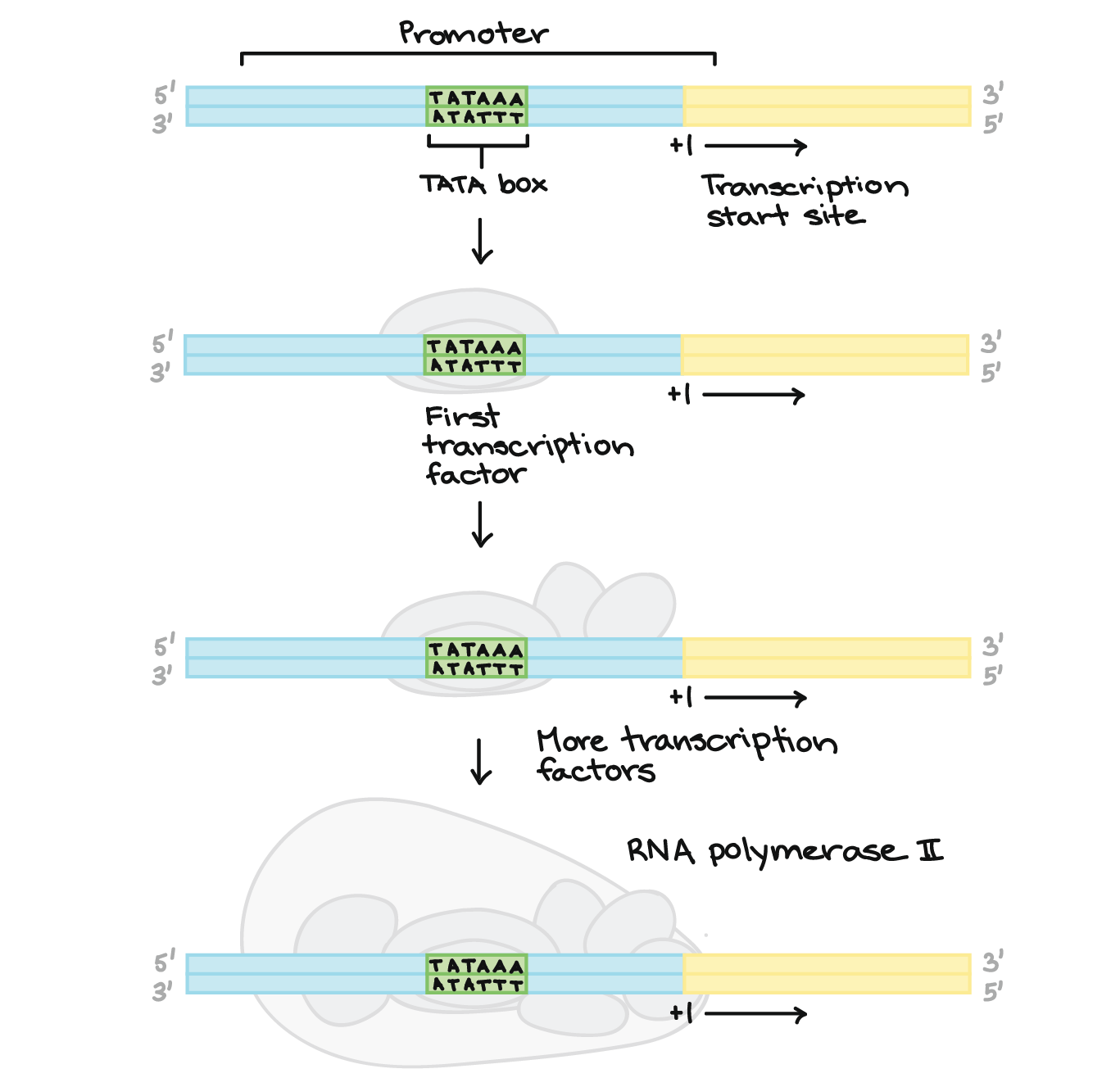
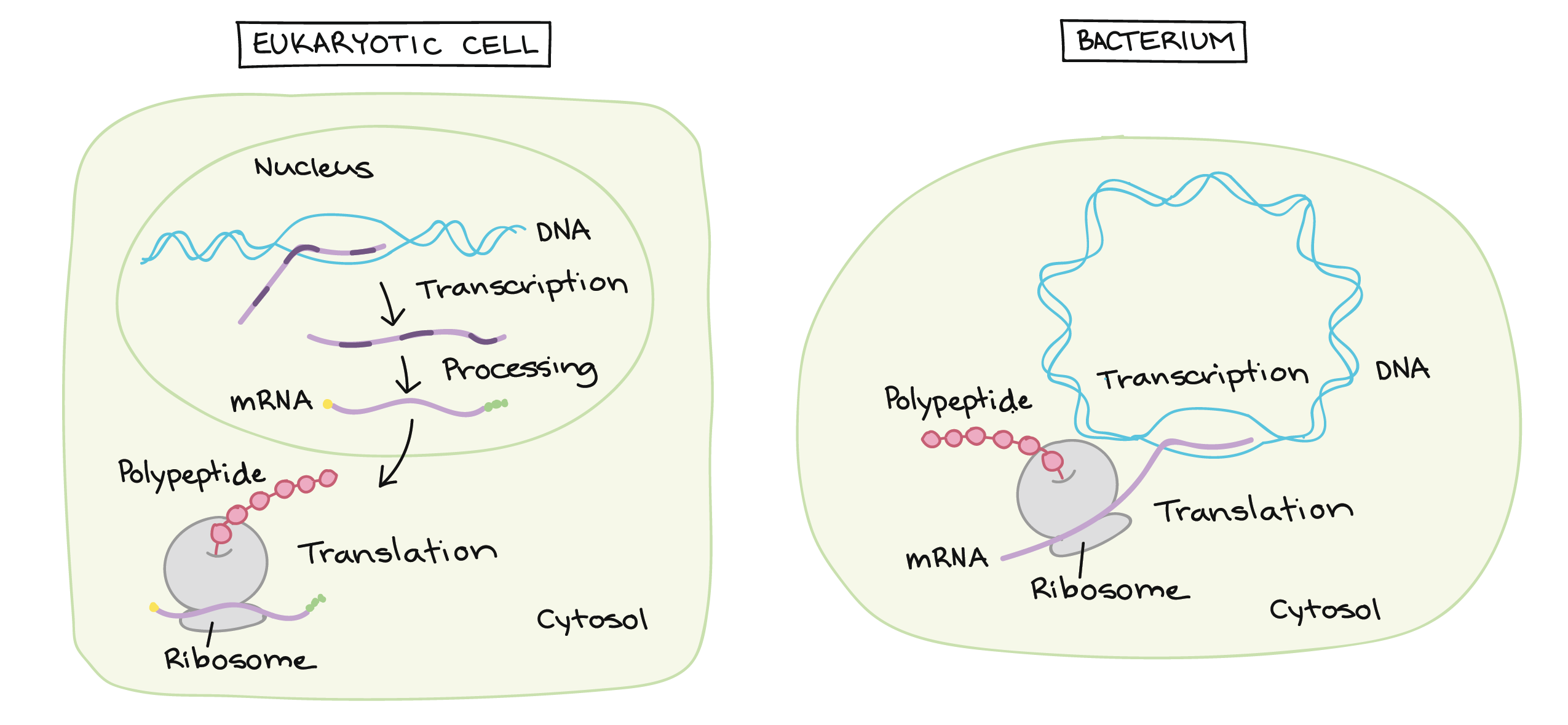
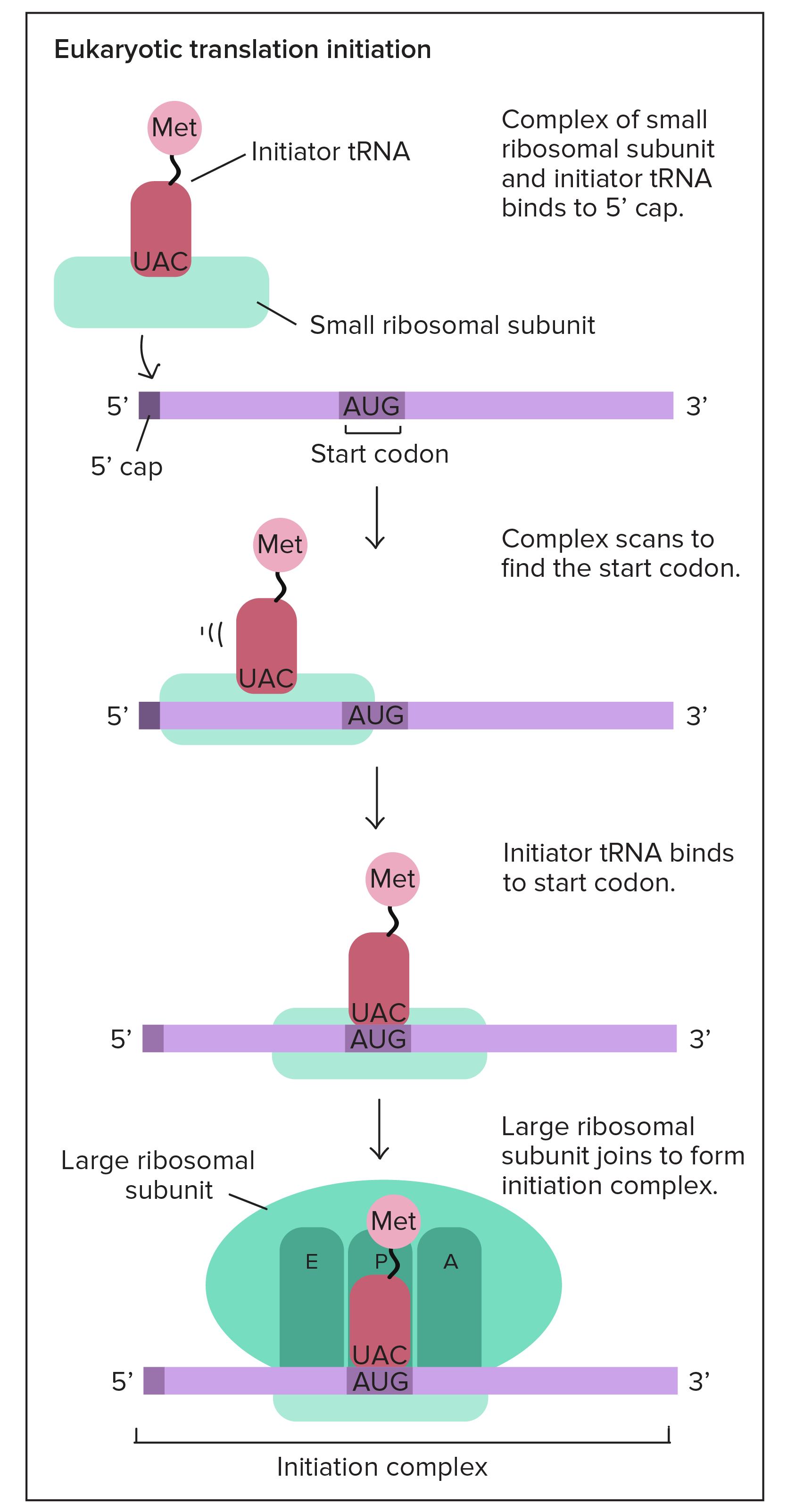
![Na transcrição, uma região de DNA se abre. Uma fita, a fita molde (ou template, do inglês), serve como gabarito para a síntese de um transcrito de RNA complementar. A outra fita, a fita codificadora, é idêntica ao RNA transcrito quanto à sequência, exceto que ela tem bases uracila (U) no lugar de bases timina (T).
Exemplo:
Fita codificante: 5'-ATGATCTCGTAA-3'
Fita molde: 3'-TACTAGAGCATT-5'
RNA transcrito: 5'-AUGAUCUCGUAA-3'
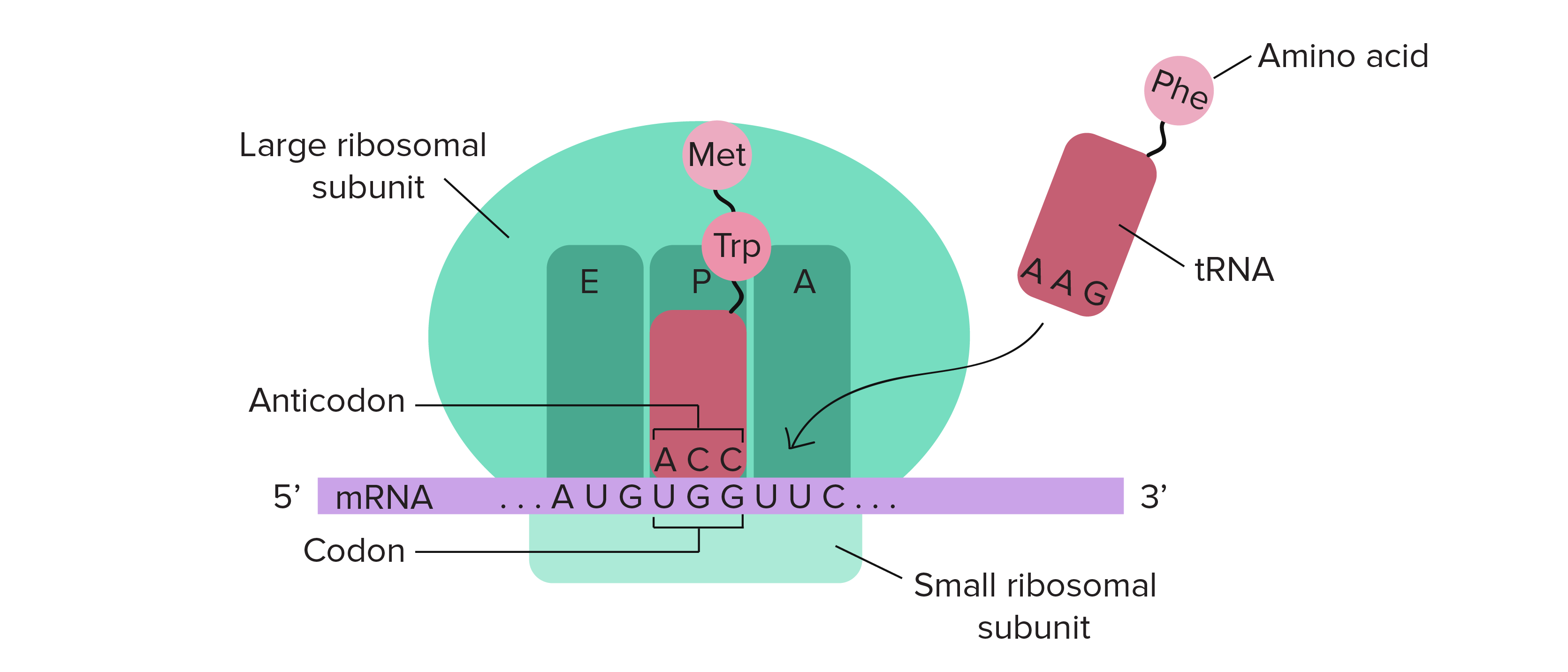
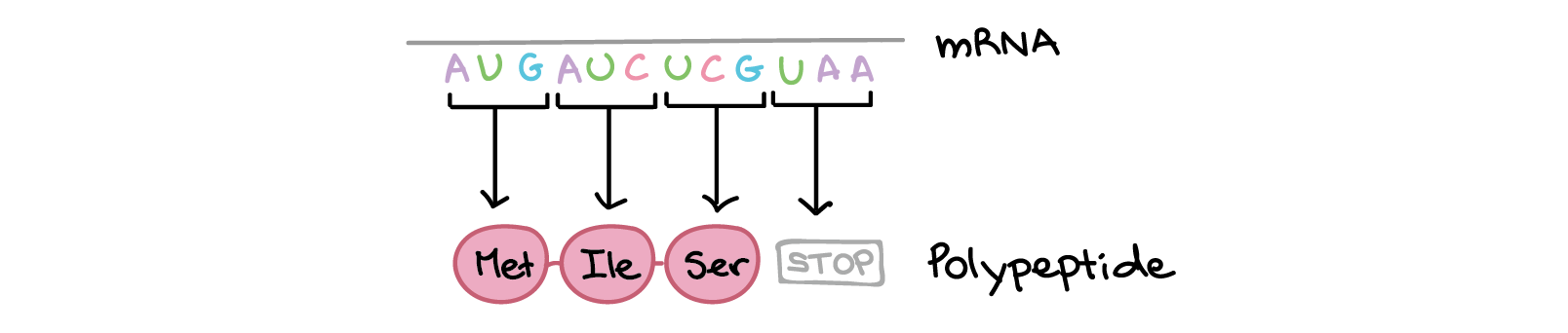
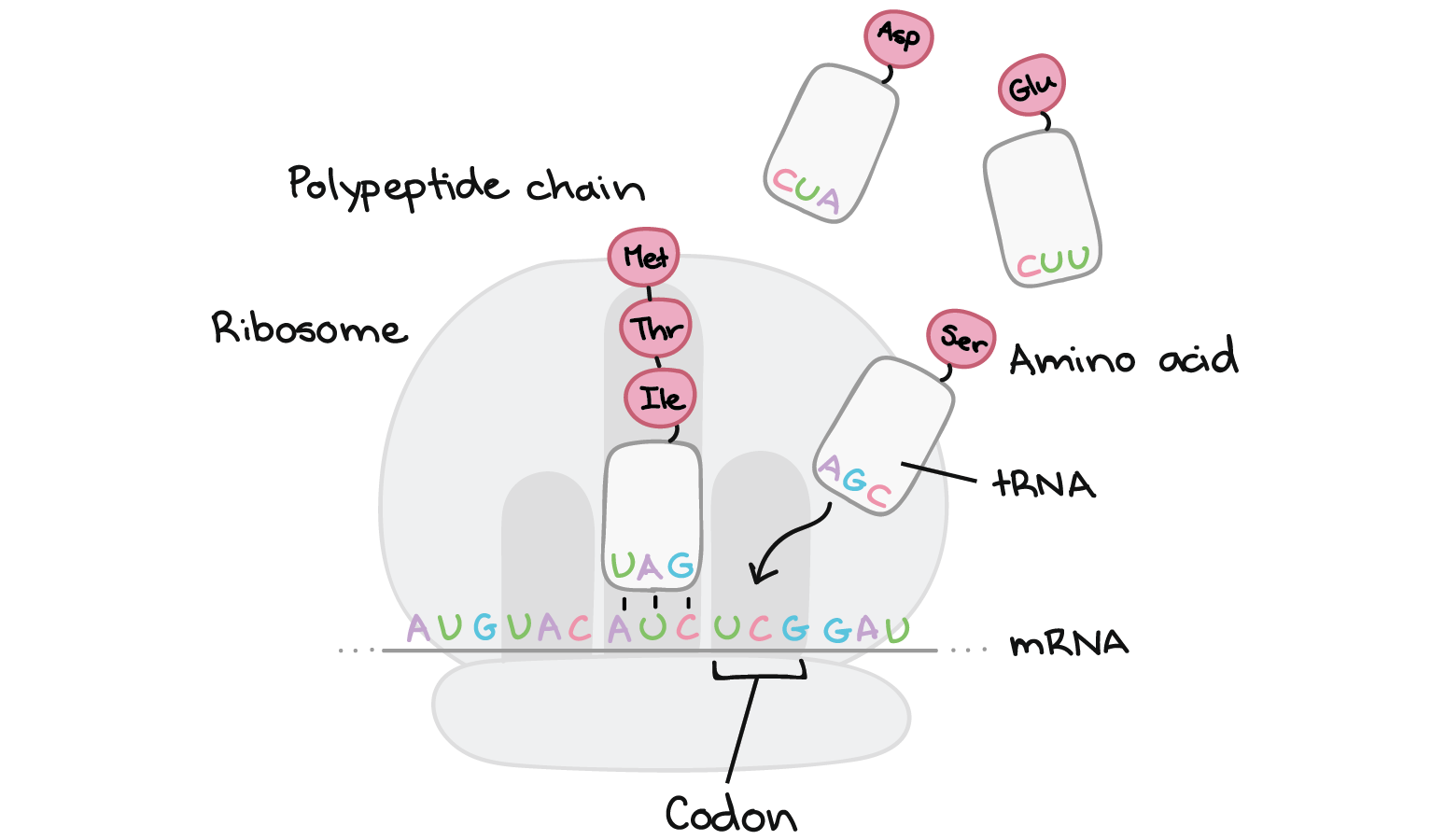
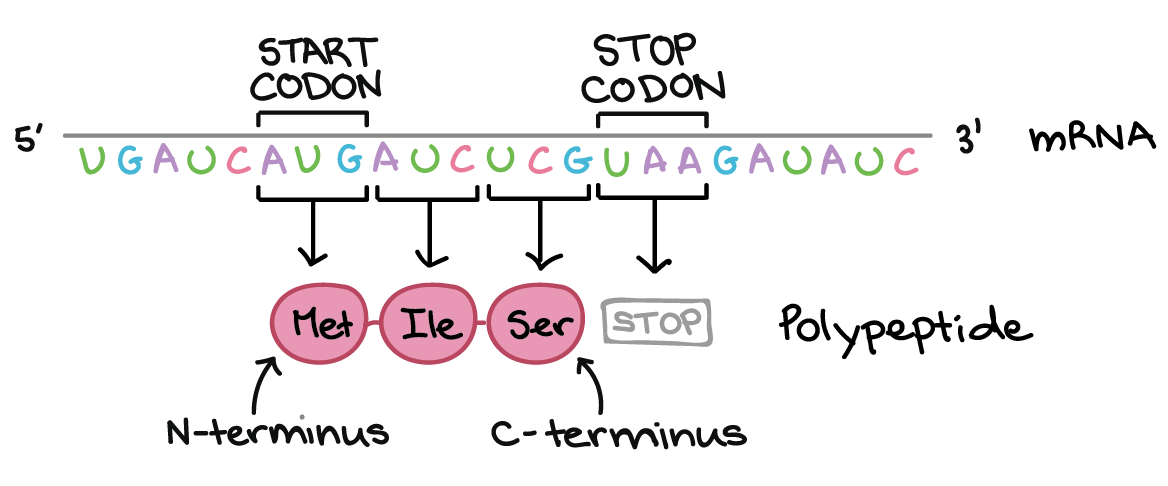
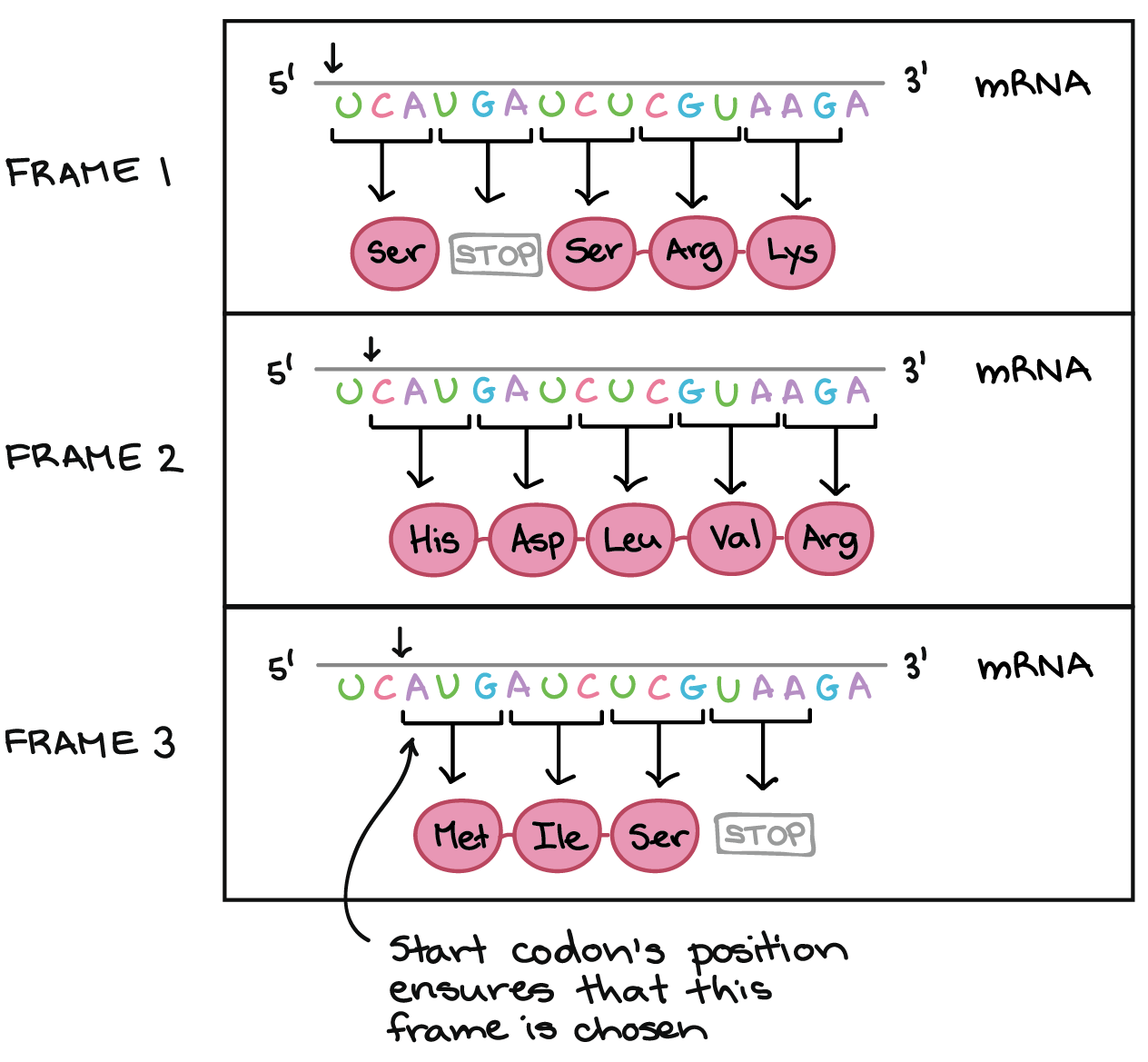
Na tradução, o RNA transcrito é lido para produzir um polipeptídeo.
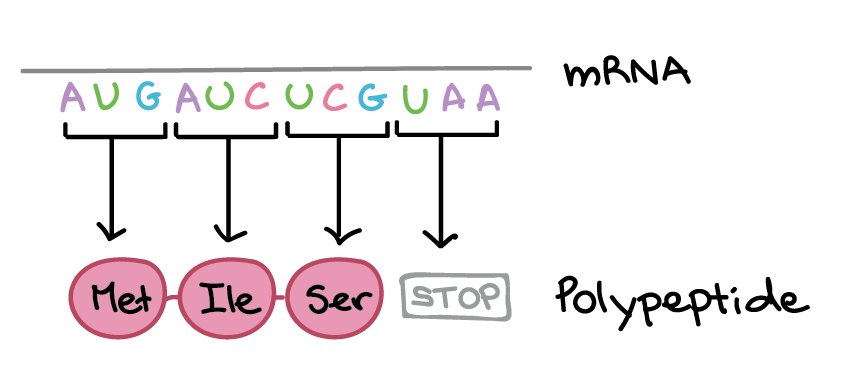
Exemplo:
Transcrito de RNA: 5'-AUG AUC UCG UAA-3'
Polipeptídeo: (N-terminal) Met - Ile - Ser - [STOP] (C-terminal)](https://cdn.kastatic.org/ka-perseus-images/534d6b2edba81dc1803eb97ba4de457c48de28af.png)